Introduction
Our primary objective in creating P2Play was to design an application that friends could use to share music among each other. We decided that the platform should be fault-tolerant, easily scalable, highly dynamic, efficient, and have no single point of failure. To accomplish this, we opted for an underlying Kademlia architecture - a structured, decentralized model that removes any possible single point of failure, while simultaneously fulfilling the requirements for optimal routing, seamless joining and leaving of peers, and effortless scalability.
Discernment
Before designing our own system, we did research on existing peer-to-peer music and file sharing systems so that we could understand the precedence of these types of systems. Our investigation started with the original Napster, which was launched in June 1999 with the primary objective of distributing audio files, particularly MP3s. The Napster architecture featured peers and a central indexing server responsible for tracking the songs available on each peer. However, due to copyright issues arising from the unregulated nature of the peer-to-peer system, Napster was eventually shut down by the US courts as people were illegally sharing copyrighted music. The court-ordered closure of the central indexing server rendered the entire network obsolete. For P2Play, we aimed to eliminate the possibility of our network being dismantled, learning from Napster’s experience and opting for a purely peer-to-peer system that avoids the single point of failure associated with a centralized server. Our research then led us to explore the Gnutella system, which featured an unstructured peer-to-peer architecture, making it an attractive candidate for a peer-to-peer system without a single point of failure. However, Gnutella’s method of locating values within the network introduced a vulnerability to distributed denial of service (DDoS) attacks. This was because searching the unstructured network required flooding it. Given this susceptibility to DDoS attacks and the inefficient search technique, we concluded that our peer-to-peer architecture should be structured in a way that allows efficient network searches while minimizing network flooding and the associated vulnerability to DDoS attacks. The final architecture we examined was Kademlia.
Kademlia
Kademlia emerged as the most suitable architecture for P2Play due to its high-performance, consistency, and efficiency in its distributed hash table (DHT) implementation. Unlike other DHT implementations, Kademlia leverages the XOR distance function to determine node proximity, with its unidirectional and symmetric properties aiding in learning about other nodes. The architecture positions peers and values as nodes in a binary tree representing the key space, with each peer occupying a unique position in the tree. This structure allows peers to maintain their own relative version of the tree as a routing table, which is subdivided into a series of buckets based on the longest common prefix shared by nodes within the bucket. Kademlia’s bucket design, with a fixed capacity k, ensures efficient routing and memory usage regulation. The protocol’s ability to guarantee that nodes are aware of at least one node in each subtree empowers any node to locate others using their ID. One of the key advantages of the Kademlia architecture is its logarithmic routing time. In a network of size n nodes, Kademlia is able to route messages to the target node in O(log(n)) time, significantly contributing to the system’s scalability and performance. This combination of features ultimately convinced us that Kademlia’s architecture would best serve as the foundation for P2Play, offering an optimal balance between efficiency, scalability, and the desired peer-to-peer architecture.
Elementary Design
Every peer in P2Play can be broken down into four primary components: the interactive shell UI, the Kademlia library, the storage, and the file server.
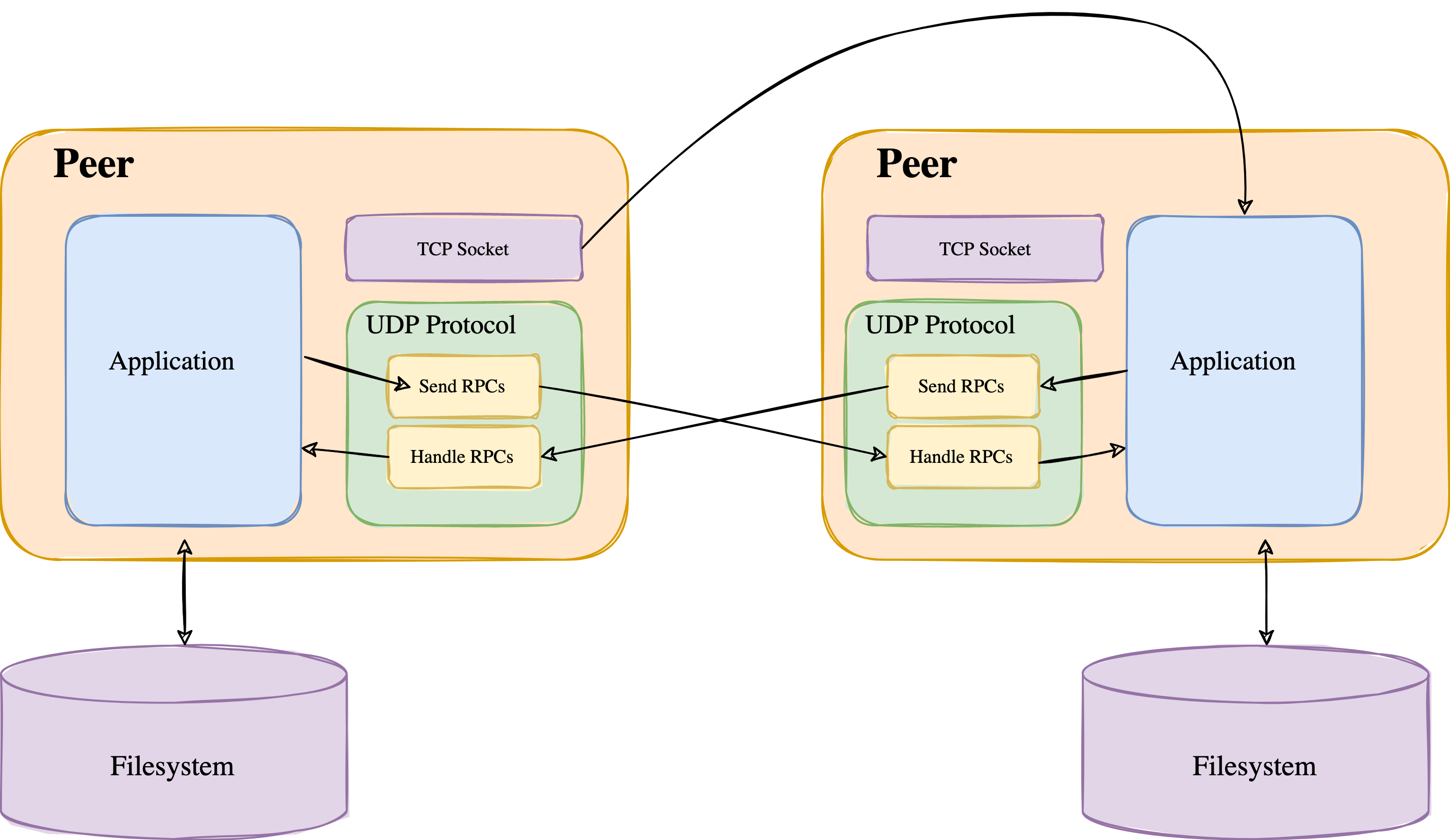
 Figure 1: Here is a diagram of the Peer Architecture. It includes the UDP protocol for the RPCs, a TCP socket for serving files, and the actual application that handles the logic.
Figure 1: Here is a diagram of the Peer Architecture. It includes the UDP protocol for the RPCs, a TCP socket for serving files, and the actual application that handles the logic.
The interactive shell provides the user a way to interact with the Kademlia library, while the file server is responsible for providing local files to other peers. The file server uses TCP for the transmission of files, while the Kademlia library uses UDP for communication with other nodes. The Kademlia library has its own in-memory storage that is used alongside the peer’s disk for song storage.
The interactive shell UI offers two methods: get(song-name, artist-name) and put(song-name, artist-name), which allows a peer to download and upload songs from and to the network, respectively. A song on the network is represented by a kad-file which is composed of the song’s metadata (song name, artist name, version number, id), and a providers list. The providers list holds <PEER ID, HOST, TCP PORT> tuples which denote the peers that are storing the actual song file on their local disk (i.e. users that have downloaded the song or already had it). Instead of storing actual files on the network, these kad-files serve as pointers to file providers. They eliminate the requirement for peers to download arbitrary file data from other peers during the upload process.
When a peer invokes the put() function, it first constructs a kad-file for the song. Since Kademlia is a DHT, all of the kad-files are distributed among the peers in the network. The hash of the song ID, which is Song Name - Artist Name, is used to locate which peers to send the kad-file to. The actual song file is initially only stored on the uploader’s disk, but other peers can become providers if they download the file.
When a user invokes the get() function, it uses the hash of the song ID to locate the kad-file for the song. If one exists, then it will go through the providers list, and try to connect to one of them via TCP and download the file. These operations will be discussed more thoroughly later in Section file-sharing.
P2Play handles the storage of both songs and kad-files. Kad-files are stored locally using a class called SongStorage. The kad-files are maintained in the class as a dictionary, where the key represents the hash of the song ID and the value consists of a tuple containing the song’s kad-file and the time it was last updated. This timestamp plays a crucial role in the key-republishing process.
In contrast, the actual song files are stored on disk, which is a more efficient and suitable storage method for larger files. This approach also allows for easier access and management of the song files when needed, as they are not intertwined with the in-memory data structures used for kad-files.
System Description
In this section, we will discuss how the underlying system actually works. The Kademlia distributed hash table (DHT) architecture contributes several features to the system that enhance P2Play’s efficient and scalable design. Kademlia organizes peers and values within a 160-bit key space. The 160-bit key space is large enough to accommodate a vast number of nodes and data while still enabling efficient routing. We used the SHA1 hashing function to facilitate the distribution of the nodes within the key space. The SHA1 hashing function is deterministic, generates hash values that are uniformly distributed, and is collision-resistant. All of these properties are important for the Kademlia DHT to work correctly. % Could talk a little more about properties of SHA1 potentially % Keyspace picture
XOR
Kademlia employs the XOR distance function to compute distances between peers or keys in the key space. A crucial aspect of Kademlia is its use of the XOR distance function to calculate the distance between nodes or keys in the key space. Combined with a cleverly organized routing table, this XOR distance function enables a $O(\log n)$ lookup time for values. The XOR operator provides these advantages due to its simplicity, identity property, and symmetry property. The identity property ensures that the XOR distance from a point in the tree to itself is 0 (i.e d(x, x) = 0 and d(x, y) > 0 for x \neq y). The symmetry property (d(x, y) = d(y, x) ∀ x, y) plays a valuable role in lookups as it guarantees a consistent distance measure between nodes. Combined with Kademlia’s organization of nodes into proximity-based buckets and its routing table maintenance, this property indirectly contributes to nodes in close proximity having similar knowledge about their surrounding network, thus enhancing the likelihood of locating the target or a nearer node within a reduced number of hops. Additionally, the XOR distance function exhibits the triangle property, where d(x, z) < d(x, y) + d(y, z). Without this property, nodes would struggle to determine which contacts from their routing table to return during a lookup. They would know the k closest nodes to the target, but there would be no guarantee that one of the other more distant contacts wouldn’t yield a shorter overall path. Finally, the XOR distance function demonstrates the unidirectional property, ensuring that for any given point x and a distance Δ > 0, there is exactly one point y such that d(x, y) = Δ. This property guarantees that all lookups for the same key converge along the same path, regardless of the originating node, further contributing to the overall efficiency and scalability of the Kademlia architecture.
Peer State
P2Play peers store contact information organized in a routing table about each other in order to route query messages. Kademlia’s basic routing table structure consists as follows: for each 0 ≤ i < 160, every peer keeps a list of at most k peers for nodes of distance between 2^i and 2^{i+1}-1 from itself. These peers are organized by last time seen, so the most recently active node is at the tail of the list and the least recently seen is at the head. When a peer receives any request or reply from another peer, it finds the appropriate bucket according to the sending peer’s ID and checks to see if the sending peer is in the receiving peer’s routing table. If the sending peer already exists in the appropriate bucket in the routing table of the recipient, then the recipient peer moves the sending peer to the tail of the list in that particular bucket. If the sending peer does not exist in the recipient peer’s routing table, then the recipient tries to greet the peer by trying to insert the sending peer to the tail of the list. However, if the bucket is full (already has k peers listed), then the recipient peer sends a PING remote procedure call to the head of the list (the least recently seen node). If the node responds, then it is moved to the tail of the list and sending peer’s information is discarded. If the peer at the head of the list does not respond, then that peer is evicted, and the recipient inserts the sending peer at the tail of the list of the appropriate bucket.
Routing Table
Kademlia’s routing table is a data structure used to store information about other nodes in the network as mentioned above. Along with the XOR distance metric, the routing table allows for efficient searching and routing. The data structure can be visualized as a binary tree where each leaf of the tree represents a bucket, and each bucket corresponds to a specific range of the 160-bit key space.
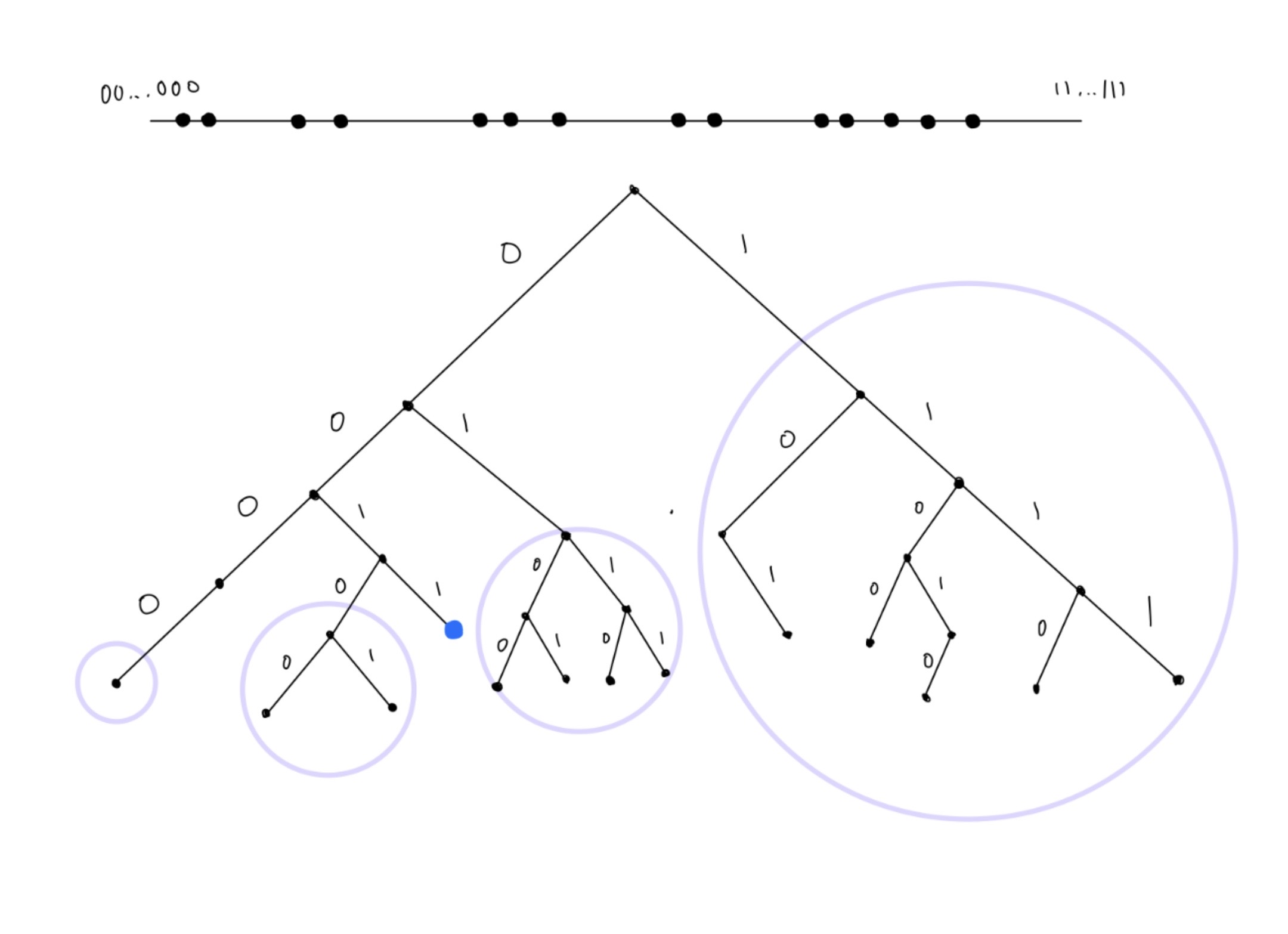 Figure 2: This diagram is a visualization of the general Kademlia routing table structure. The blue dot represents a peer, and the circles represent buckets in the key space that the indicated node (blue dot) must have at least one contact in if it exists.
Figure 2: This diagram is a visualization of the general Kademlia routing table structure. The blue dot represents a peer, and the circles represent buckets in the key space that the indicated node (blue dot) must have at least one contact in if it exists.
The internal peers of the tree are used to organize these buckets based on the proximity of the key space, while the leaves (buckets) are responsible for storing information about the nodes that share a particular range of key space proximity. Each bucket contains a list of at most k peers. This division helps to refine and improve the granularity of the routing table, allowing for more efficient and targeted searches. Since nodes can quickly identify relevant buckets containing the target key, they can narrow down the search space effectively. The basic Kademlia protocol says that each bucket covers a range of 2^i .. 2^{i+1}-1 for 0 ≤ i < 160 as mentioned above. In practice, however, in order to handle highly unbalanced trees a slight adjustment is made. When the system begins, there exists only one bucket that covers the entire key space. As nodes join the network, they are all added to the lone bucket. When the bucket reaches capacity k and a new node wants to join the bucket, instead of having a strict number of buckets, we implement a bucket split. When we perform a bucket split, we literally split the bucket in half (range//2) into two new buckets, left and right, and redistribute the nodes from the original bucket into the appropriate bucket according to their ID. It is important to visualize that when a bucket is split, the longest common prefix of each node in the bucket increases by 1, which effectively divides the range of the key space that the bucket represents into two smaller ranges. This division helps to refine and improve the granularity of the routing table, allowing for more efficient and targeted searches. In P2Play, bucket splitting occurs 4 out of 5 times when a new node is encountered, and this contributes to a more accurate representation of the network’s structure. The other 1 out of 5 times, the original eviction policy is followed, which involves evicting the least recently seen node in the bucket to accommodate the new node. This combination of bucket splitting and eviction policy helps maintain a balanced routing table while ensuring that the network remains adaptive to changes in node proximity and availability.
Protocol
Remote Procedure Calls
Kademlia offers 4 RPCs for peer communication: PING, STORE, FIND_NODE, and FIND_VALUE. The PING RPC probes a node to check if it is online and reachable. The STORE RPC adds or updates the key-value pair in the recipient nodes’s local storage based on the received information. This RPC is used to distribute and replicate data across the network. The FIND_NODE RPC returns tuples of <NODE_ID, IP, UDP_PORT> for the k-closest nodes in the recipient peer’s routing table to a given ID. This elementary RPC is used in the general lookup algorithm. The FIND_VALUE RPC returns the corresponding value for a given key if the peer has it in its local storage. If it does not, then the call will behave as a FIND_NODE call, returning the k-closest nodes.
The most important procedure that a peer must perform in order for the system to work is to locate the k-closest nodes to a given ID. This procedure is the core driver that allows Kademlia and P2Play function and it is called node lookup. Given an ID in the key space, this function is responsible for recursively crawling the network to find the k-closest nodes to the given ID. A peer, Peer1 starts the algorithm by searching its own routing table for the k-closest peers to the given ID. If there are less than k peers in Peer1’s routing table, then those are returned. These k-closest nodes are then stored in a KClosestPeers list which essentially acts as a heap - sorting the nodes in the list by XOR distance to the target ID. Peer1 then chooses the closest α, the concurrency parameter, peers from the KClosestPeers list and sends FIND_NODE RPCs to each of them asynchronously. The nodes returned from the RPC calls are then inserted into the KClosestPeers list. The algorithm then continues the iteration, choosing the α closest peers from the list and sending them FIND_NODE RPCs. The algorithm repeats until all of the k-closest nodes in the KClosestPeers list have been contacted, guaranteeing that the k-closest peers in the network are stored in that list.
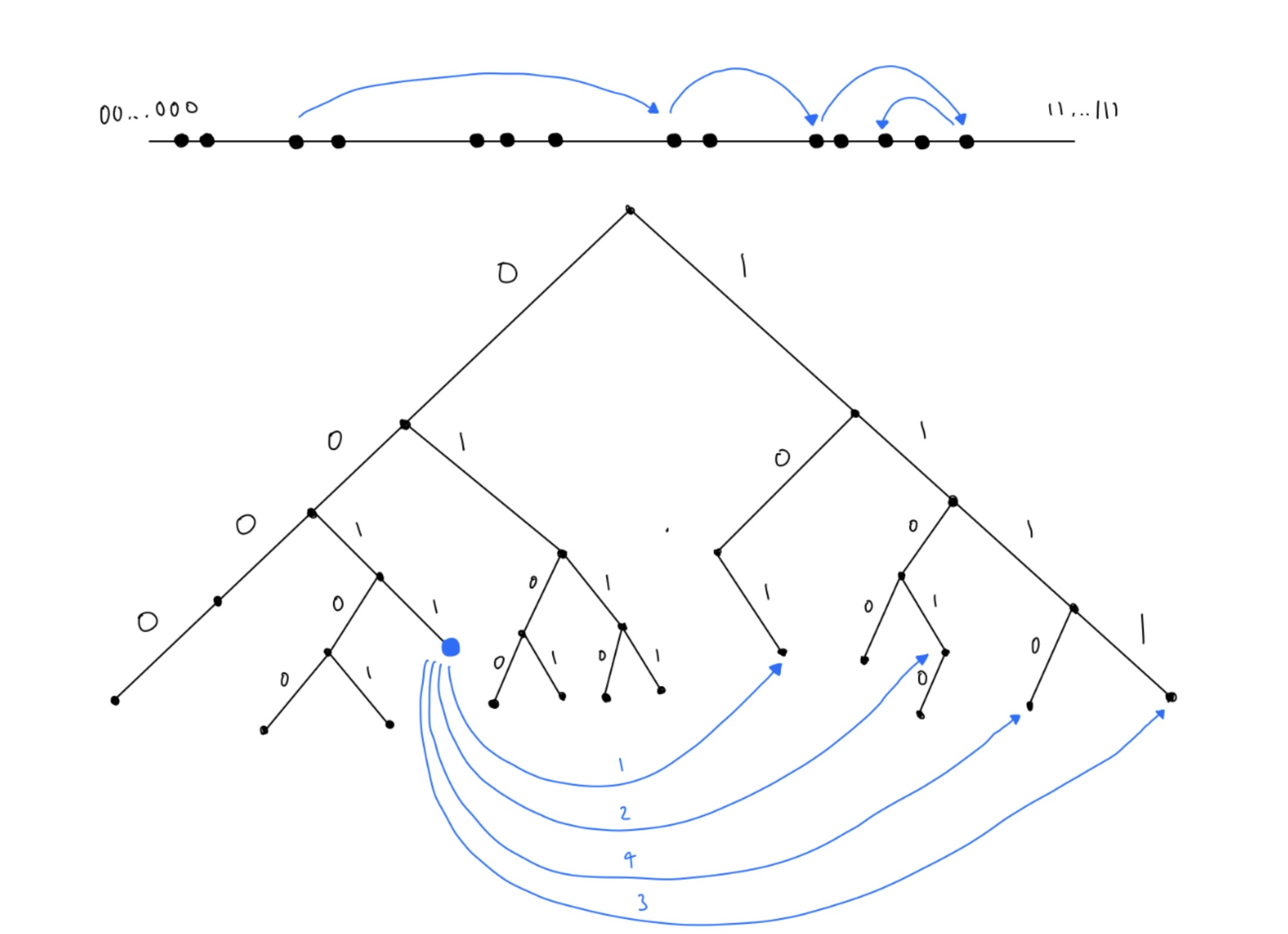 Figure 3: This figure is a visualization of how the node lookup process works. Node 0011 is trying to find a node 101 by its ID. 0011 first sends a FIND_NODE RPC to 101 which it is already in 0011’s routing table. From the results of this RPC, subsequent RPC’s are made and the node 101 is eventually found. As you can see from the key-space visualization, nodes are able to almost half the distance with every query, and this is how Kademlia ensures log(n) routing time.
Figure 3: This figure is a visualization of how the node lookup process works. Node 0011 is trying to find a node 101 by its ID. 0011 first sends a FIND_NODE RPC to 101 which it is already in 0011’s routing table. From the results of this RPC, subsequent RPC’s are made and the node 101 is eventually found. As you can see from the key-space visualization, nodes are able to almost half the distance with every query, and this is how Kademlia ensures log(n) routing time.
File Sharing
As described in the Elementary Design Section, P2Play offers two main APIs for file sharing: get() and put().
When a user invokes the put() function, the system first constructs a kad-file. The song_name and artist_name fields in the kad-file are filled in by user input, and the id is a randomly assigned number. To calculate the version number, the peer must first identify the maximum version number of the song already in the network, if it exists. This is accomplished by crawling the network using the node_lookup method, sending various FIND_VALUE RPCs. This enables the identification of the k-closest peers to the song’s key. Subsequently, the kad-file version is set to the maximum version number found (0 if not found) incremented by one. This protocol with the version number guarantees that the system will be eventually consistent. This is because if a peer possesses a kad-file for a song in its local storage and receives a STORE request for the same song, it will only replace the existing kad-file if the incoming kad-file has a higher version number. In the event of a tie, the kad-file ID serves as the tiebreaker. Because of key-republishing, the highest-version document will ultimately prevail within the network in the presence of other versions.
When a user invokes the get() function, the system crawls the network using the node_lookup method, sending various FIND_VALUE RPCs. This procedure will locate the k-closest kad-files to the song ID, and return the kad-file with the highest version number. If no kad-files exist for the given song ID, the user is notified that the song does not exist on the network. If the kad-file does exist, then the system can use the list of providers and their file server addresses to create a TCP connection. If a connection is successful, the peer wanting to download a file will send a message with the song it wants to download. The file server of the provider will process this message and send the file contents via TCP socket if it has the file. In the case of a successful download, the downloading peer generates a new kad-file that is derived from the old one adding itself to the list of providers and incrementing the version number by one. It then transmits a STORE messages containing the new kad-file to the k-closest peers list acquired from the network crawl. These STORE RPCs are done asynchronously in the background.
Key-Republishing
Since peers can join and leave the network voluntarily, P2Play needs a way of persisting the data already on the network. There are two different events that can occur that can cause lookups for valid keys to fail. The first case is if peers who previously received STORE request to store a particular kad-file leave the network. The other case is if new peers join the network with IDs closer to a particular key than the peers actually storing the key-value pair. Because of this, a method of data persistence is necessary in order to maintain key properties of P2Play like data persistence, redundancy, and eventual consistency.
In P2Play, peers republish all their key-value pairs every hour, with the exception of those that have been stored within the last hour (i.e., if a peer receives a key-value pair, it will not republish this pair during the upcoming hourly interval). The rationale behind this exception is that when a peer receives a STORE request, it can be assumed that k-1 other peers have also received the same request. As a result, there is no need to republish key-value pairs obtained from a STORE request within the same hour, since they have likely already been propagated across the network.
Key-republishing plays a crucial role in ensuring the eventual consistency of the P2Play system. When a peer receives a STORE request for a key-value pair that already exists in its storage, it only updates its kad-file if the incoming kad-file has a greater version number. Through key-republishing, the k-closest peers to a song ID will constantly be updated to the most-recent version of the song. This process enables the system to achieve eventual consistency.
Bucket Refreshing
Similar to key-republishing, P2Play refreshes buckets every hour if they have not been involved in a node lookup during that time frame. Bucket refreshing serves several purposes, such as updating stale entries, discovering new peers, and preserving network connectivity. By initiating a FIND_NODE request on a random ID that the bucket range covers, the peer acquires information about active peers within the bucket’s range. Consequently, the peer can update its routing table with current information and eliminate any stale or unreachable peers. Since the network is dynamic and peers can join or leave at any given moment, refreshing buckets enables the peer to identify new peers that have entered the network and fall within the same bucket’s range, thus maintaining an up-to-date routing table. Moreover, bucket refreshing contributes to the overall network connectivity and robustness by ensuring that peers periodically verify the availability of their neighbors. This minimizes the likelihood of network partitions and enhances the efficiency of lookups and other operations.
Graphs and Analysis
Upload Latency
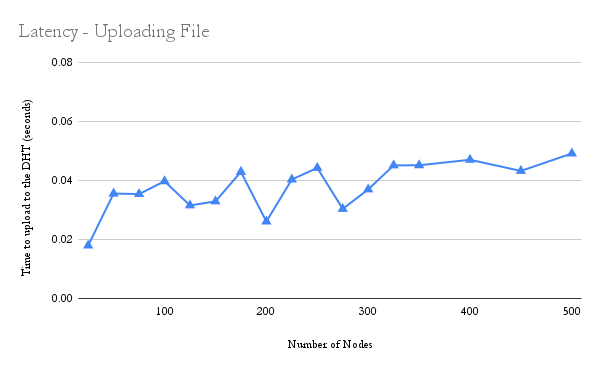 The upload latency vs the number of nodes graph shows a slight upward trend when the number of nodes is below 50. As more nodes are added to the system, the time taken to find the k-closest nodes will take longer. As the number of nodes increases beyond 60-70 nodes, we do not see an increasing trend. This could be the result of the
The upload latency vs the number of nodes graph shows a slight upward trend when the number of nodes is below 50. As more nodes are added to the system, the time taken to find the k-closest nodes will take longer. As the number of nodes increases beyond 60-70 nodes, we do not see an increasing trend. This could be the result of the O(log(n)) routing time characteristic of the Kademlia protocol, since the log(100) is not much less than the log(200) and so on.
Download Latency
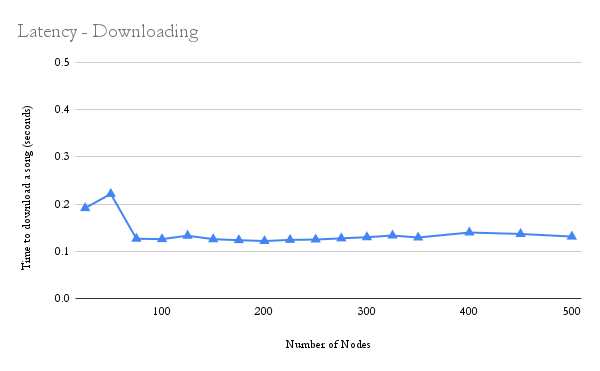 The download latency vs number of nodes graph shows the same slight trend of latency increase while the number of nodes is increasing to about 60-70 nodes; then, there is a drop off, and finally the latency remains consistent. This is likely due to similar reasons as the upload latency trend vs number of nodes. In order to download a song, the peer must find the k-closest nodes to the song’s ID. Since the routing is
The download latency vs number of nodes graph shows the same slight trend of latency increase while the number of nodes is increasing to about 60-70 nodes; then, there is a drop off, and finally the latency remains consistent. This is likely due to similar reasons as the upload latency trend vs number of nodes. In order to download a song, the peer must find the k-closest nodes to the song’s ID. Since the routing is O(log(n)), it makes sense that the latency would increase at first but level off as the number of nodes became much larger.
Bootstrap Latency
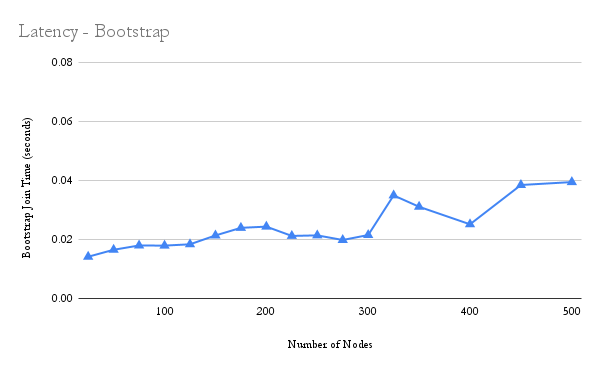 The bootstrap latency vs the number of nodes also shows a slight upward trend as the number of nodes increase. This makes sense because when a node joins the system, it performs the
The bootstrap latency vs the number of nodes also shows a slight upward trend as the number of nodes increase. This makes sense because when a node joins the system, it performs the node_lookup on its bootstrap with itself as the target. As more and more nodes join the system, the more iterations (and thus more time) it takes to crawl the network.
Find_Node Calls in Bootstrapping
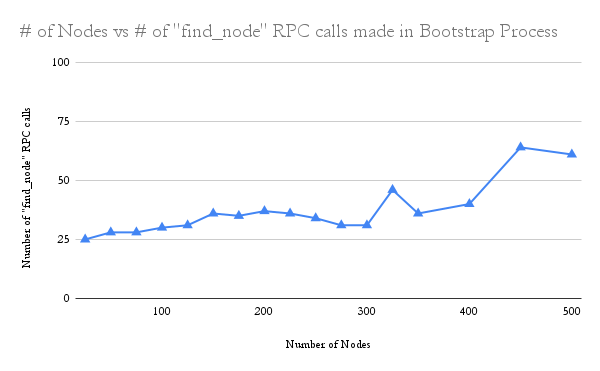 The graph shows a trend resulting from the increasing number of nodes on the network vs the number of
The graph shows a trend resulting from the increasing number of nodes on the network vs the number of find_node calls made during the bootstrapping process. Generally, there seems to be not much variance at first. For the first 350 nodes, the number of find_node calls remains at about 30. Then it drastically doubles over the next 100 or so nodes. As nodes join, the number of RPC calls generally increases.
Find_Node Calls in Uploading
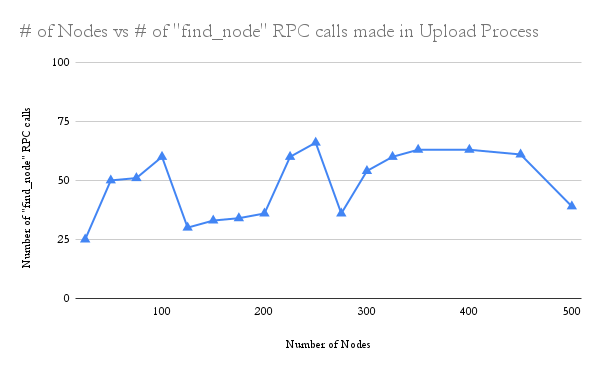 The graph shows the number of
The graph shows the number of find_node calls done during the upload process as the number of nodes increases. As the number of nodes increase, generally the number of RPC calls increase.
Find_Node Calls in Downloading
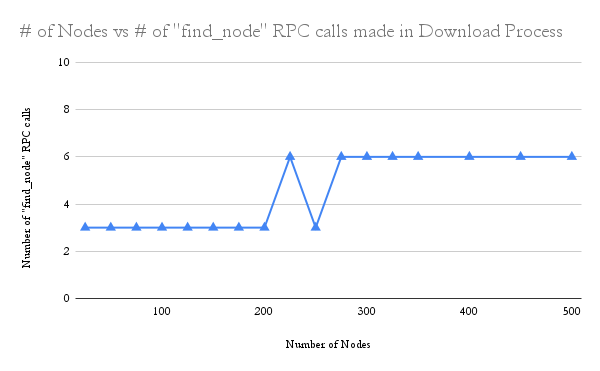 The graph shows the number of
The graph shows the number of find_node calls required to download a song versus the number of nodes in the network. When nodes get find_value calls, they return the value immediately. This results in fewer find_node calls needed, compared to the upload process. Since we could only test with 500 nodes, and k was 20, the amount of calls needed to find nodes with the value were very little.